Under the hood: Branch and Bound algorithm
General frame algorithm for solving discrete problems.
- Prerequisites
Brute force approach and enumeration of feasible solutions
We have seen in case of the festivals example, that brute force approach is a probably very slow, but valid approach to find an optimal solution when the search space is discrete and finite. Some acceleration ideas have also been mentioned, some of which may could be applied in a more general manner. Let's focus on enumerating only the feasible solutions now.
Enumerating all of the solutions was simple for the festivals, travesing through all of the subsets of a set is a simple task to do. We would only need to count from 0 to \(2^n-1\) and interpret the numbers binary representation as a subset indicator. Many of those subsets are, however, infeasible, and things get a little bit more difficult, if we want to generate the feasible solutions only. Try to figure out an approach to do so by yourself, or just click the button below. Show solution
There are many ways to do this, but a simple approach would be to follow these steps:
We wither go to F1 or not.
- If we don't go to F1, we wither go to F2 or not
- If we don't go to either F1 or F2, we can ither go to F3 or not
- If we don't go to F1,F2,F3, we have to go to F4 because that's the last option for Apocalyptica and Haggard
- If we go to F4, but not to F1, F2, or F3, we have to go to F5, as that is the last option for several bands.
- We go to F4 and F5, but not to F1,F2,F3. There are no decisions left, and we have a solution with 2 festivals.
- If we go to F4, but not to F1, F2, or F3, we have to go to F5, as that is the last option for several bands.
- If we don't go to F1,F2,F3, we have to go to F4 because that's the last option for Apocalyptica and Haggard
-
If we don't go to F1 or F2, but go to F3, we have to go F4 because that's the last option for Apocalyptica and Haggard
- If we go to F3 and F4, but not to F1 or F2, we wither go to F5 or not.
- If we go to F3 and F4, but not F1,F2 or F5, we have a solution with two festivals.
- If we go to F3,F4 and F5, but not F1 or F2, we have a solution with three festivals.
- If we go to F3 and F4, but not to F1 or F2, we wither go to F5 or not.
- If we don't go to either F1 or F2, we can ither go to F3 or not
- If we go to F2, but not to F1, we can either go to F3 or not...
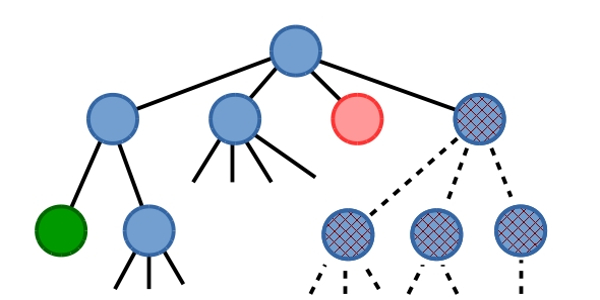
A tree-style enumeration of the feasible solutions can be observed in the above approach:
- The root of the tree represents the case, when no decisions are made.
- The leafs represent solutions, where all the decisions are made.
- At each non-leaf node, a decision is made with all the possible outcomes "encoded" in its children.
Another way to look at the same tree is:
- The root represents the set of all of the feasible solutions.
- The leafs are single solutions, or more precisely: solution sets with a single element inside of them.
- At each non-leaf node, a deacision is made, that divides the nodes' set into subsets, that will be its children.
The "Branch" part
The approach described above can be generalized to any problems with discrete decisions:
- Take the set of all of the feasible solutions, and assign them to the root node of a tree.
- For each tree node, whose set is not a singleton, select a decision, that has to be made, and parition the set assigned to that node so, that each subset contains the solutions having a specific outcome. Assign these subsets to children nodes. No children nodes are made for empty subsets.
- If the set of a node is a singleton, that node will be a leaf, and the solution can be evaluated
In practice, the sets assigned to nodes are usually not generated and partitioned explicitely. Instead, the outcomes of the former decisions are kept, and at each node it is somehow checked, whether:
- There is at least one feasible solution with the former decision outcomes.
- If yes, are there more than one solutions in that set?
If we already have the above branching algorithm, it can easily be extended with a minimum search on the leafs.
The "Bound" part
Let us consider a simple shortest path problem: I am currently living in Győr, and my parents live in Nagykanizsa. Let us assume, that I want to drive home the shortest way possible, only using main roads (roads with 1 and 2 digit numbers), but no highways to avoid additional fees.
A simple way to split all of the feasible routes to subsets is to make a decision on the first part of my track, which can be either:
- Driving on road 1 to Mosonmagyaróvár
- Driving on road 85 to Csorna
- Driving on road 83 to Városlőd
- Driving on road 82 to Veszprém
- Driving on road 81 to Kisbér
- Driving on road 1 (in the other direction) to Komárom
A children node is created for all of these 6 options, and for example, the fourth node represents all of the solutions that start with
- Driving on road 8 to Városlőd
- Driving on road 77 to Lesencetomaj
- Driving on road 73 to Csopak
- Driving on road 8 to the crossing near Litér
This can be repeated for all of the nodes, until we reach Nagykanizsa. If the "partial route" of a node ends at Nagykanizsa, it must be a leaf node, as that route is the only feasible solution with no circle that has that beginning. The length of the route can be evaluated and used in the minimum search.
This approach, however, is not very efficient. Assume, that we have already found the following leaf node: "Győr - Veszprém - Csopak - Balatonederics - Keszthely - Fenékpuszta - Balatonszentgyörgy - Nagykanizsa" with 217 km. When we find this solution, there may be other uninvestigated nodes with partial routes, for example: "Győr - Komárom - Budapest - Szolnok". If we were to blindly follow the instructions above, we would create two children nodes (branch this solution set into two) for following the direction towards either Jászberény or Törökszentmiklós.
We can, however, observe, that the route until Szolnok is already 227 km long, that is longer than a feasible solution we have found so far. Thus, there is no meaning in finding solutions in this subtree (in the set assigned to this node), as they will definitely be worse than a solution formerly found, hence not optimal. So, we can prune this node (solution subset) from the search, and look for another one.
What we did essentially is to give a lower bound on all of the solutions in that subtree (in the set assigned to the node), and if it was worse than the best solution found so far, the subtree (solution subset) was pruned. This idea can be generalized to any problem class, if there is a way to provide a lower bound on a subset of solutions. A general, pseudo-code like structure of the Branch-and-Bound frame algorithm looks like this:
- Set \(min\) to \(\infty\)
- Let \({\cal S}=\{ S \}\), where \(S\) is the set of all of the feasible solutions.
- While \(\cal S\) is not empty:
- Select and remove an element from \(\cal S\), and denote it with \(P\)
- If the lower bound on the solutions in \(P\) is greater than \(min\), then prune this set, and continue with another set from \(\cal S\) if there is one.
- Otherwise:
- If \(P\) is a singleton, chech the value of that solution, and update \(min\) if it is better than that.
- If \(P\) is not a singleton, find a decision that can further partition it, creating \(P_1,P_2,\dots\), then put the non-empty subsets into \(\cal S\)
- If \(min\) is not infinity, it has an optimal solution, and there is no feasible solution otherwise
Note, that this is a frame algorithm, that can be used for a lot of problem classes, where the details have to be specified, e.g.:
- How is \(P\) selected, i.e., what is the rule of selecting the next uninvestigated node in the tree?
- Which decision is selected for a node?
- How does the bound function work?
- How can we decide if \(P\) is singleton or empty?
For example, we used the length of the "already traveled path" as the lower bound, and made branches based on the next segment in the path.
Note about bounding functions
The "tightness" of a bounding function can be the most important contributor to the efficiency of an algorithm. If the bound is not tight, i.e., the bound is far from the actual value of the best solution in \(P\), then pruning will only happen deeper in the tree, and a subtree is investigated unnecessarily. To understand this, let's go back to our pruned path, "Győr - Komárom - Budapest - Szolnok". The parent of this node was "Győr - Komárom - Budapest", and it has 7 siblings. The bound of the parent is 126 km, which is way below of the 217 km long solution we have found earlier, so all 8 children nodes are generated. If we look at the map, we can see intuitievely, that this is really a wrong direction to go, as Budapest is east from Gyor, while Nagykanizsa is to the south-west. What this means, that just by looking at the map, we know, that none of the solutions in this subtree (in the set assigned to "Győr - Komárom - Budapest") will be better than the one we have already found. Still we need to generate the children, and in some cases the grandchildren to prove it, as our bound is not tight enough.
Our previous bound did not include anything about the distance, that is still to be traveled from the end of the current path. However, it is not difficult to provide a lower bound for that either. Simply we should add the geographical distance between the end of the current path and Nagykanizsa. For the "Győr - Komárom - Budapest" node, this Budapest-Nagykanizsa distance is 190 km. Adding the two together: 126 + 190 = 316 km, which is still a valid lower bound, as any "ending" of that path will be longer than 190 km. 316 km is way over 227, so with this tigther bound we can prune the "Győr - Komárom - Budapest" node, and we will not have to spend time generating and evaluating its children, grandchildren.
It seems, that we always have to strive towards tighter and tighter bounds to keep the B&B tree as small as possible. Tighter bounds, however, often require more complex calculations. A slightly tigther bound may not prune enough nodes to make up for the additional time spent on calculating that complex bound at each node. Selecting the best performing bound is not a trivial task, and is often done on a statistical basis.